#SQL Join Elimination
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Users from the US are the majority of Tumblr visitors.
Text
Optimizing Database Queries: Join Elimination and Foreign Key Strategies
In the realm of database management and optimization, the strategic use of foreign keys often garners attention for its potential to enhance or detract from system performance. The concept of join elimination, facilitated through the implementation of foreign keys, emerges as a compelling topic for those seeking to streamline query execution. This article delves into the nuanced considerations…
View On WordPress
#Database Performance Enhancement#efficient database design#Foreign Key Strategies#Optimizing T-SQL Queries#SQL Join Elimination
0 notes
Text
Lightning Engine: A New Era for Apache Spark Speed

Apache Spark analyses enormous data sets for ETL, data science, machine learning, and more. Scaled performance and cost efficiency may be issues. Users often experience resource utilisation, data I/O, and query execution bottlenecks, which slow processing and increase infrastructure costs.
Google Cloud knows these issues well. Lightning Engine (preview), the latest and most powerful Spark engine, unleashes your lakehouse's full potential and provides best-in-class Spark performance.
Lightning Engine?
Lightning Engine prioritises file-system layer and data-access connector optimisations as well as query and execution optimisations.
Lightning Engine enhances Spark query speed by 3.6x on TPC-H workloads at 10TB compared to open source Spark on equivalent equipment.
Lightning Engine's primary advancements are shown above:
Lightning Engine's Spark optimiser is improved by Google's F1 and Procella experience. This advanced optimiser includes adaptive query execution for join removal and exchange reuse, subquery fusion to consolidate scans, advanced inferred filters for semi-join pushdowns, dynamic in-filter generation for effective row-group pruning in Iceberg and Delta tables, optimising Bloom filters based on listing call statistics, and more. Scan and shuffle savings are significant when combined.
Lightning Engine's execution engine boosts performance with a native Apache Gluten and Velox implementation designed for Google's hardware. This uses unified memory management to switch between off-heap and on-heap memory without changing Spark settings. Lightning Engine now supports operators, functions, and Spark data types and can automatically detect when to use the native engine for pushdown results.
Lightning Engine employs columnar shuffle with an optimised serializer-deserializer to decrease shuffle data.
Lightning Engine uses a parquet parser for prefetching, caching, and in-filtering to reduce data scans and metadata operations.
Lightning Engine increases BigQuery and Google Cloud Storage connection to speed up its native engine. An optimised file output committer boosts Spark application performance and reliability, while the upgraded Cloud Storage connection reduces metadata operations to save money. By providing data directly to the engine in Apache Arrow format and eliminating row-to-columnar conversions, the new native BigQuery connection simplifies data delivery.
Lightning Engine works with SQL APIs and Apache Spark DataFrame, so workloads run seamlessly without code changes.
Lightning Engine—why?
Lightning Engine outperforms cloud Spark competitors and is cheaper. Open formats like Apache Iceberg and Delta Lake can boost business efficiency using BigQuery and Google Cloud's cutting-edge AI/ML.
Lightning Engine outperforms DIY Spark implementations, saving you money and letting you focus on your business challenges.
Advantages
Main lightning engine benefits
Faster query performance: Uses a new Spark processing engine with vectorised execution, intelligent caching, and optimised storage I/O.
Leading industry price-performance ratio: Allows customers to manage more data for less money by providing superior performance and cost effectiveness.
Intelligible Lakehouse integration: Integrates with Google Cloud services including BigQuery, Vertex AI, Apache Iceberg, and Delta Lake to provide a single data analytics and AI platform.
Optimised BigQuery and Cloud Storage connections increase data access latency, throughput, and metadata operations.
Flexible deployments: Cluster-based and serverless.
Lightning Engine boosts performance, although the impact depends on workload. It works well for compute-intensive Spark Dataframe API and Spark SQL queries, not I/O-bound tasks.
Spark's Google Cloud future
Google Cloud is excited to apply Google's size, performance, and technical prowess to Apache Spark workloads with the new Lightning Engine data query engine, enabling developers worldwide. It wants to speed it up in the following months, so this is just the start!
Google Cloud Serverless for Apache Spark and Dataproc on Google Compute Engine premium tiers demonstrate Lightning Engine. Both services offer GPU support for faster machine learning and task monitoring for operational efficiency.
#ApacheSpark#LightningEngine#BigQuery#CloudStorage#ApacheSparkDataFrame#Sparkengine#technology#technews#technologynews#news#govindhtech
0 notes
Text
Data Science Course With Placement: Your Path to a Guaranteed Career
If you're looking to break into the tech world with a promising future, a data science course with placement is your best bet. With the increasing demand for skilled data professionals across industries, choosing a job guarantee data science course ensures you don’t just learn—you get placed.
Unlike general certifications, these job-assured programs give you industry-relevant skills and full career support. Whether you're a fresh graduate or a working professional looking to pivot, this is your path to joining the top hiring companies.
Why Choose a Job Guarantee Data Science Course?
Choosing the right course can be overwhelming, but when you opt for a job guarantee data science course, you eliminate the guesswork. These programs are designed to give learners the confidence that their time and money are being invested wisely.
Here’s why a placement-assured course is worth your attention:
You get trained in real-time tools and techniques used in the industry.
You are guaranteed placement assistance or a job after course completion.
You receive mentorship, mock interviews, and profile-building support.
You can explore top data science job roles across various sectors.
You gain practical exposure with real datasets, not just theory.
Key Features of the Best Data Science Program India Offers
The right data science program India will not only cover technical content but also provide the right mix of projects, mentorship, and placement support.
Here’s a short introduction before we go into the features:
With hundreds of online and offline courses out there, the best ones stand out with a hands-on, practical, and career-ready approach. Here's what to look for:
Live sessions by industry experts
Interactive assignments and case studies
Capstone projects with real data
Certifications from recognised institutes
Soft skills and interview training
Personalised mentorship and doubt-clearing sessions
Access to hiring networks and job portals
What You’ll Learn in a Data Science Course With Placement
In these courses, you get an all-around understanding of core and advanced concepts. From basics to expert-level skills, the journey is structured for real-world use cases.
Here's a 50-word explanation:
The course helps you build a strong foundation and then dive deep into complex tools and techniques. You’ll develop both technical expertise and analytical thinking required in top data science job roles.
You’ll master:
Python, SQL, R Programming
Statistics and Probability
Machine Learning Algorithms
Data Visualisation using Tableau & Power BI
Model Deployment and Cloud Tools
Big Data and NLP Basics
Git, GitHub, and Docker for Version Control
Career Support: From Training to Placement
The real value of a data science course with placement lies in its career support. These programs don’t stop at teaching—they help you land a job.
Here’s a brief before the bullet points:
Don’t worry. You’ll be supported throughout your career journey. From creating your first resume to preparing for technical interviews, you’ll be guided every step of the way.
Career services typically include:
1:1 Career Coaching and Guidance
Resume and LinkedIn Profile Building
Mock Interviews with Feedback
HR and Technical Interview Training
Access to Hiring Drives
Job Tracking and Application Support
Top Data Science Job Roles You Can Get
Once you complete a job guarantee data science course, a range of high-paying, in-demand roles becomes available to you. You’re not restricted to one career path.
Here’s a short 50-word intro:
Data science is a vast domain with various subfields. Depending on your strengths, you can explore roles in analytics, engineering, or research.
Some top roles include:
Data Analyst
Data Scientist
Machine Learning Engineer
Business Intelligence Analyst
Data Engineer
NLP Specialist
AI/ML Research Associate
Which Companies Hire Data Science Talent?
The biggest reason learners opt for a data science course with placement is access to top hiring companies. These companies value candidates from structured, career-focused programs.
Here’s a 50-word intro:
Well-established training institutes have direct tie-ups with hiring partners. These companies actively recruit from such courses because the learners are job-ready and well-trained.
Some top recruiters include:
Accenture
EY
TCS
Wipro
Deloitte
Infosys
Flipkart
Capgemini
IBM
Tech Mahindra
What Makes a Job Guarantee Data Science Course Different?
While many courses teach data science, very few back it up with job assurance. A job guarantee data science course is structured with real accountability.
Let’s understand what makes them different:
Placement is contractually promised after course completion.
No placement = Refund clauses in select institutes.
Programs continue mentoring you until you're placed.
Personalised career plans and ongoing support make success more likely.
Real-time performance tracking ensures your progress is monitored.
These features build trust, especially for learners investing time and resources to switch or grow in their careers.
How to Choose the Right Data Science Program in India?
When selecting a data science program India offers, look for transparency and outcomes. Not every course offers real job assurance or access to the top hiring companies.
Here’s a quick 50-word explanation:
With so many options, you need to be smart about picking the right program. Make sure the course includes practical training, experienced mentors, live sessions, and strong placement records.
Checklist before enrolling:
Does it offer 100% job assurance in writing?
Are the trainers industry professionals?
Are career services included?
Is it a project-based curriculum?
Are they tied up with recruitment partners?
FAQs
Q1. Can a non-tech person do a data science course with placement? Yes, why not! Many courses are beginner-friendly and start with the basics. A background in maths or logic is helpful but not mandatory.
Q2. What’s the duration of a job guarantee data science course? Most full-time programs range from 4 to 9 months. Some part-time or weekend options extend up to a year.
Q3. Is job guarantee really reliable? If you enrol with a reputed institute, the job assurance is contractually promised, making it dependable and risk-free.
Q4. Do these courses provide interview preparation? Yes, these programs majorly include resume writing, mock interviews, and even direct placement support through hiring partners.
Q5. What is the salary expectation after completing this course? Entry-level roles typically start at ₹4–6 LPA, but with experience and project exposure, you can grow fast to ₹10+ LPA roles.
Conclusion
If you're serious about building a career in tech- choosing a data science course with placement is indeed a smart move. With structured training, real-world projects, and solid career support, you're more likely to land roles in top companies. Make sure to pick a job guarantee data science course that offers the right data science program India needs—practical, guided, and future-ready.
0 notes
Text
Why Learning Excel Is Still Important in 2025

With the thinly spread modern-world app environment and AI tools out there, one would esitmate if Excel really holds its weight in 2025. The simple answer is that it does. While newer platforms get glamorous attention, Microsoft Excel has been and remains quietly supporting businesses, managing data, and ensuring decision support throughout the industries.
An Everlasting Skill
Excel has been around for decades and in 2025 the demand for Excel remains so great that employers don't stop asking for it. The reason? Its flexibility, mighty power, and universal applicability. In short, from looking at sales trends, budgets, and automation of workflows, Excel does everything. It does it fast.
Excel Automation and AI
The Microsoft Corporation hasn't let Excel age. With AI-intelligent features such as "Ideas" and dynamic arrays, users would be able to automate reports, retrieve insights in a matter of seconds, all but eliminating human errors-without having to write a single line of code.
Industry Versatile
Excel is pertinent to any field it means finance, marketing, engineering, or education. It offers help in visualizing data through charts, pivot tables, and dashboards, simplifying complex information to make it understandable and actionable.
A Stepping Stone Into More Powerful Tools
Excel is akin to learning to drive before learning to pilot an airplane. It usually leads to Power BI, SQL, and Python and is, therefore, essential for data-driven careers.
Conclusion
So yes, while tools evolve, Excel’s relevance hasn’t faded—it’s evolved too. In 2025, being good at Excel doesn’t just make you competent; it makes you future-ready.
At TCCI, we don't just teach computers — we build careers. Join us and take the first step toward a brighter future.
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
#Basic Computer Course in Bopal Ahmedabad#Best Computer Classes in Iskcon-Ambli road in Ahmedabad#Computer Training Institute near Bopal Ahmedabad#computer training institute near me#TCCI - Tririd Computer Coaching Institute
0 notes
Text
This SQL Trick Cut My Query Time by 80%
How One Simple Change Supercharged My Database Performance
If you work with SQL, you’ve probably spent hours trying to optimize slow-running queries — tweaking joins, rewriting subqueries, or even questioning your career choices. I’ve been there. But recently, I discovered a deceptively simple trick that cut my query time by 80%, and I wish I had known it sooner.

Here’s the full breakdown of the trick, how it works, and how you can apply it right now.
🧠 The Problem: Slow Query in a Large Dataset
I was working with a PostgreSQL database containing millions of records. The goal was to generate monthly reports from a transactions table joined with users and products. My query took over 35 seconds to return, and performance got worse as the data grew.
Here’s a simplified version of the original query:
sql
SELECT
u.user_id,
SUM(t.amount) AS total_spent
FROM
transactions t
JOIN
users u ON t.user_id = u.user_id
WHERE
t.created_at >= '2024-01-01'
AND t.created_at < '2024-02-01'
GROUP BY
u.user_id, http://u.name;
No complex logic. But still painfully slow.
⚡ The Trick: Use a CTE to Pre-Filter Before the Join
The major inefficiency here? The join was happening before the filtering. Even though we were only interested in one month’s data, the database had to scan and join millions of rows first — then apply the WHERE clause.
✅ Solution: Filter early using a CTE (Common Table Expression)
Here’s the optimized version:
sql
WITH filtered_transactions AS (
SELECT *
FROM transactions
WHERE created_at >= '2024-01-01'
AND created_at < '2024-02-01'
)
SELECT
u.user_id,
SUM(t.amount) AS total_spent
FROM
filtered_transactions t
JOIN
users u ON t.user_id = u.user_id
GROUP BY
u.user_id, http://u.name;
Result: Query time dropped from 35 seconds to just 7 seconds.
That’s an 80% improvement — with no hardware changes or indexing.
🧩 Why This Works
Databases (especially PostgreSQL and MySQL) optimize join order internally, but sometimes they fail to push filters deep into the query plan.
By isolating the filtered dataset before the join, you:
Reduce the number of rows being joined
Shrink the working memory needed for the query
Speed up sorting, grouping, and aggregation
This technique is especially effective when:
You’re working with time-series data
Joins involve large or denormalized tables
Filters eliminate a large portion of rows
🔍 Bonus Optimization: Add Indexes on Filtered Columns
To make this trick even more effective, add an index on created_at in the transactions table:
sql
CREATE INDEX idx_transactions_created_at ON transactions(created_at);
This allows the database to quickly locate rows for the date range, making the CTE filter lightning-fast.
🛠 When Not to Use This
While this trick is powerful, it’s not always ideal. Avoid it when:
Your filter is trivial (e.g., matches 99% of rows)
The CTE becomes more complex than the base query
Your database’s planner is already optimizing joins well (check the EXPLAIN plan)
🧾 Final Takeaway
You don’t need exotic query tuning or complex indexing strategies to speed up SQL performance. Sometimes, just changing the order of operations — like filtering before joining — is enough to make your query fly.
“Think like the database. The less work you give it, the faster it moves.”
If your SQL queries are running slow, try this CTE filtering trick before diving into advanced optimization. It might just save your day — or your job.
Would you like this as a Medium post, technical blog entry, or email tutorial series?
0 notes
Text
Online vs Offline Data Analytics Courses in Noida – What Should You Choose?
In today’s data-driven world, Data Analytics has emerged as one of the most sought-after skills across industries. Whether you’re a student aiming to build a strong career foundation or a working professional planning to upskill, enrolling in a Data Analytics course is a smart move. But there’s one question that often pops up – Should you choose an online or offline Data Analytics course in Noida?
Let’s break it down for you!
Online Data Analytics Courses – Learn Anytime, Anywhere
Online learning has revolutionized education. With just a laptop and an internet connection, you can dive into the world of data from the comfort of your home. Here are some key benefits:
Flexibility & Convenience Whether you’re a college student or a working professional, online classes offer unmatched flexibility. Learn at your own pace and revisit concepts as many times as needed.
Access to Recorded Lectures & Resources Missed a class? No worries. Most online courses provide recorded lectures, downloadable materials, and lifetime access to the content.
Learn from Industry Experts Online platforms often bring in seasoned professionals who are actively working in the field of data science and analytics. This gives learners exposure to real-world scenarios and the latest trends.
Cost-Effective Online courses generally come with affordable fees and eliminate travel or relocation costs.
Offline Data Analytics Courses – Learn with Hands-on Support
Offline or classroom-based learning still holds its charm – especially for those who prefer face-to-face interaction and structured learning environments.
Interactive Learning Offline classes provide a collaborative atmosphere where students can ask questions, participate in discussions, and engage in peer learning.
Real-Time Support In-person guidance from trainers helps in better understanding of complex topics, especially when it comes to tools like Excel, Power BI, Python, and SQL.
Structured Schedules Classroom sessions follow a fixed timetable, which helps learners stay disciplined and consistent.
Lab Sessions & Group Projects Offline learning often includes practical lab sessions and team projects that simulate real-world data problems.
So, What Should You Choose?
At Appwars Technologies, we say – Why choose when you can have both?
We offer flexible learning modes for our Data Analytics courses in Noida – both online and offline. Whether you’re someone who thrives in a classroom or needs the freedom to learn on your own schedule, we’ve got you covered.
Join our offline batches at our Noida center for in-person mentorship, hands-on labs, and group collaboration. Opt for our online live sessions and recorded content to learn from anywhere, at your convenience. Get industry-certified training, real-time projects, and 100% placement assistance – no matter the mode you choose.
0 notes
Text
Healthcare Jobs in 2025: What You Need to Get Hired

The Healthcare Job Market is Changing- Are You Ready?
The healthcare industry is evolving rapidly and the competition for healthcare jobs in 2025 is fiercer than ever. New technologies, automation, and changing employer expectations are reshaping the job landscape. If you’re a healthcare professional or a medical student, you might be wondering how to stay relevant in this competitive field, which skills and technologies you need to learn, and what employers are actually looking for.
The good news? While the competition for healthcare jobs in 2025 is intense, those who stay ahead of industry trends will have more job opportunities. This guide will walk you through the most in-demand skills, tools, and strategies to help you land a top healthcare job in 2025.
How to Stay Relevant and Land Top Healthcare Jobs in 2025
1. Keep Learning and Upskilling
Take online courses in AI in healthcare, health informatics, and telemedicine.
Stay updated on new medical research and emerging technologies.
Attend medical conferences and webinars to network and gain insights from industry leaders.
2. Get Hands-On Experience with New Technologies
Enroll in free EHR training programs from providers like Epic Systems.
Participate in hospital-run telemedicine initiatives to get practical experience.
Work with AI-assisted diagnostic tools to understand their real-world applications.
3. Build a Professional Network
Join professional organizations like HIMSS (Healthcare Information and Management Systems Society).
Engage in LinkedIn healthcare groups to connect with industry professionals.
Seek mentorship from experienced professionals in your specialization.
What Skills and Technologies Do You Need to Learn?
1. Digital & Technological Proficiency
EHR Systems: Epic Systems, Cerner, Meditech
Telemedicine Platforms: Teladoc Health, Amwell, eClinicalWorks
AI in Healthcare: IBM Watson Health, UpToDate, Nuance Dragon Medical One
Data Analytics: SQL, Power BI, Tableau
2. Soft Skills That Matter
Clear Communication: Explain medical conditions in layman’s terms.
Adaptability: Quickly learn new systems and adjust to changing work environments.
Leadership & Team Collaboration: Efficiently work in high-pressure environments and coordinate care teams.
What Are Employers Actually Looking For?
1. Candidates Who Can Handle Healthcare Technology
Employers prefer candidates who can navigate EHRs, use telehealth solutions, and interpret AI-driven diagnostics.
Demonstrating experience with these tools on your resume makes you stand out.
2. Certifications That Prove Your Expertise
AI in Healthcare: AI in Healthcare Specialization (Stanford, Coursera)
Telehealth Training: Harvard Medical School’s Telehealth Certification
Medical Coding & Billing: Certified Professional Coder (CPC) by AAPC
Health Informatics: HIMSS Healthcare IT Certifications
3. Strong Soft Skills and Problem-Solving Abilities
Employers need professionals who can handle complex patient care situations with empathy and efficiency.
Time management and the ability to work well in fast-paced healthcare settings are critical.
What’s Changing in Healthcare Hiring?
1. Employers Expect Tech-Savvy Professionals
Gone are the days when healthcare jobs were just about clinical expertise. Now, hospitals and healthcare organizations expect professionals to be comfortable with digital tools like:
Electronic Health Records (EHRs)
Telemedicine platforms
AI-powered diagnostics
2. More Competition Than Ever
With more graduates entering the field and experienced professionals shifting roles, the healthcare job market is more crowded than ever. Standing out means having the right skills and certifications.
3. AI & Automation Are Reshaping Roles
Automation is eliminating repetitive tasks like medical transcription and basic diagnostics. However, professionals who understand how to work alongside AI will have a significant advantage.
4. Soft Skills Still Matter
Even with all the tech advancements, healthcare remains a people-focused field. Employers are prioritizing:
Clear patient communication
Crisis management skills
Team collaboration and adaptability
Must-Have Skills & Tools to Secure Healthcare Jobs in 2025
1. Master Key Healthcare Technologies
Being proficient in the right healthcare tools can give you an instant edge. These are the top systems to familiarize yourself with:
Electronic Health Records (EHR) Systems
Top Platforms: Epic Systems, Cerner, Meditech
Why It Matters: Over 90% of hospitals in the U.S. use EHRs. If you can navigate them efficiently, you’re already ahead of many candidates.
Telemedicine & Remote Patient Monitoring
Top Platforms: Teladoc Health, Amwell, eClinicalWorks
Why It Matters: Virtual care is here to stay. Understanding how to conduct remote consultations and manage digital patient records is a must.
AI in Healthcare & Clinical Decision Support Systems (CDSS)
Top Platforms: IBM Watson Health, UpToDate, Nuance Dragon Medical One
Why It Matters: AI is already being used to assist in diagnostics, treatment planning, and documentation—and its role will only expand.
Medical Imaging & Radiology AI Tools
Top Platforms: Aidoc, Butterfly iQ, Arterys
Why It Matters: AI-powered imaging tools improve speed and accuracy in diagnostics. Professionals with experience using them will have a competitive advantage.
How to Stand Out in Job Applications & Interviews
1. Build a Future-Proof Resume
Highlight tech skills (EHRs, telehealth, AI tools).
Showcase real patient impact (quantify improvements in care—e.g., reduced patient wait times by 20% using EHR optimization).
Keep it ATS-friendly (use keywords relevant to the job description).
2. Gain Hands-On Experience with the Right Tools
Take free EHR training (Epic Systems offers online courses).
Join telehealth pilot programs (Hospitals are constantly expanding virtual care services).
Enroll in AI-in-healthcare bootcamps (Coursera, Udacity, and HIMSS offer courses).
3. Prepare for AI-Assisted & Behavioral Interviews
Optimize your resume for AI screening by using industry-relevant keywords.
Prepare for real-world case scenarios, like handling a virtual consultation or responding to a cybersecurity breach.
Stay Ahead & Secure Your Future in Healthcare
With the rapid evolution of the healthcare industry, securing healthcare jobs in 2025 requires mastering both technical and soft skills.
From telemedicine and AI-driven diagnostics to EHR systems and cybersecurity awareness, the demand for tech-savvy healthcare professionals is growing. Employers are also looking for professionals with strong communication, crisis management, and leadership abilities.
Don’t wait—start learning one new skill today and take control of your career growth.
Ready to land your dream healthcare job? Check out Vaidyog, India’s largest healthcare job portal. Find top job opportunities, get free resume-building resources, and stay updated on industry trends. Visit Vaidyog now!
0 notes
Text
Tips for Understanding Computer Databases for Homework Assignments

In today’s digital world, databases play a crucial role in managing and organizing vast amounts of information. Whether you're a student learning database concepts or working on complex assignments, understanding computer databases can be challenging. This blog will guide you through essential tips for mastering computer databases and help you complete your homework efficiently. If you're looking for computer database assistance for homework, All Assignment Experts is here to provide expert support.
What is a Computer Database?
A computer database is a structured collection of data that allows easy access, management, and updating. It is managed using a Database Management System (DBMS), which facilitates storage, retrieval, and manipulation of data. Popular database systems include MySQL, PostgreSQL, MongoDB, and Microsoft SQL Server.
Why is Understanding Databases Important for Students?
Databases are widely used in industries like banking, healthcare, and e-commerce. Students pursuing computer science, information technology, or data science must grasp database concepts to build a strong foundation for future careers. Database knowledge is essential for managing large data sets, developing applications, and performing data analysis.
Tips for Understanding Computer Databases for Homework Assignments
1. Master the Basics First
Before diving into complex queries, ensure you understand basic database concepts like:
Tables and Records: Databases store data in tables, which contain rows (records) and columns (fields).
Primary and Foreign Keys: Primary keys uniquely identify each record, while foreign keys establish relationships between tables.
Normalization: A technique to eliminate redundancy and improve database efficiency.
2. Learn SQL (Structured Query Language)
SQL is the standard language for managing databases. Some essential SQL commands you should learn include:
SELECT – Retrieve data from a database.
INSERT – Add new records to a table.
UPDATE – Modify existing records.
DELETE – Remove records from a table.
JOIN – Combine data from multiple tables.
Using online SQL playgrounds like SQL Fiddle or W3Schools can help you practice these commands effectively.
3. Use Online Resources and Tools
Numerous online platforms provide computer database assistance for homework. Websites like All Assignment Experts offer professional guidance, tutorials, and assignment help to enhance your understanding of databases. Other useful resources include:
W3Schools and TutorialsPoint for database tutorials.
YouTube channels offering step-by-step database lessons.
Interactive coding platforms like Codecademy.
4. Work on Real-Life Database Projects
Practical experience is the best way to solidify your knowledge. Try creating a small database for:
A library management system.
An online store with customer orders.
A student database with courses and grades.
This hands-on approach will help you understand real-world applications and make it easier to complete assignments.
5. Understand Database Relationships
One of the biggest challenges students face is understanding database relationships. The three main types include:
One-to-One: Each record in Table A has only one corresponding record in Table B.
One-to-Many: A record in Table A relates to multiple records in Table B.
Many-to-Many: Multiple records in Table A relate to multiple records in Table B.
Using Entity-Relationship Diagrams (ERDs) can help visualize these relationships.
6. Debug SQL Queries Effectively
If your SQL queries aren’t working as expected, try these debugging techniques:
Break queries into smaller parts and test them individually.
Use EXPLAIN to analyze how queries are executed.
Check for syntax errors and missing table relationships.
7. Seek Expert Assistance When Needed
If you find yourself struggling, don’t hesitate to seek help. All Assignment Experts offers computer database assistance for homework, providing expert solutions to your database-related queries and assignments.
8. Stay Updated with Advanced Database Technologies
The database field is constantly evolving. Explore advanced topics such as:
NoSQL Databases (MongoDB, Firebase): Used for handling unstructured data.
Big Data and Cloud Databases: Learn about databases like AWS RDS and Google BigQuery.
Data Security and Encryption: Understand how databases protect sensitive information.
Conclusion
Understanding computer databases is crucial for students handling homework assignments. By mastering basic concepts, practicing SQL, utilizing online resources, and working on real projects, you can excel in your database coursework. If you need professional guidance, All Assignment Experts provides top-notch computer database assistance for homework, ensuring you grasp key concepts and score better grades.
Start applying these tips today, and you’ll soon develop a solid understanding of databases!
#computer database assistance for homework#computer database assistance#education#homework#do your homework
1 note
·
View note
Text
Best DBT Course in Hyderabad | Data Build Tool Training
What is DBT, and Why is it Used in Data Engineering?
DBT, short for Data Build Tool, is an open-source command-line tool that allows data analysts and engineers to transform data in their warehouses using SQL. Unlike traditional ETL (Extract, Transform, Load) processes, which manage data transformations separately, DBT focuses solely on the Transform step and operates directly within the data warehouse.
DBT enables users to define models (SQL queries) that describe how raw data should be cleaned, joined, or transformed into analytics-ready datasets. It executes these models efficiently, tracks dependencies between them, and manages the transformation process within the data warehouse. DBT Training

Key Features of DBT
SQL-Centric: DBT is built around SQL, making it accessible to data professionals who already have SQL expertise. No need for learning complex programming languages.
Version Control: DBT integrates seamlessly with version control systems like Git, allowing teams to collaborate effectively while maintaining an organized history of changes.
Testing and Validation: DBT provides built-in testing capabilities, enabling users to validate their data models with ease. Custom tests can also be defined to ensure data accuracy.
Documentation: With dbt, users can automatically generate documentation for their data models, providing transparency and fostering collaboration across teams.
Modularity: DBT encourages the use of modular SQL code, allowing users to break down complex transformations into manageable components that can be reused. DBT Classes Online
Why is DBT Used in Data Engineering?
DBT has become a critical tool in data engineering for several reasons:
1. Simplifies Data Transformation
Traditionally, the Transform step in ETL processes required specialized tools or complex scripts. DBT simplifies this by empowering data teams to write SQL-based transformations that run directly within their data warehouses. This eliminates the need for external tools and reduces complexity.
2. Works with Modern Data Warehouses
DBT is designed to integrate seamlessly with modern cloud-based data warehouses such as Snowflake, BigQuery, Redshift, and Databricks. By operating directly in the warehouse, it leverages the power and scalability of these platforms, ensuring fast and efficient transformations. DBT Certification Training Online
3. Encourages Collaboration and Transparency
With its integration with Git, dbt promotes collaboration among teams. Multiple team members can work on the same project, track changes, and ensure version control. The autogenerated documentation further enhances transparency by providing a clear view of the data pipeline.
4. Supports CI/CD Pipelines
DBT enables teams to adopt Continuous Integration/Continuous Deployment (CI/CD) workflows for data transformations. This ensures that changes to models are tested and validated before being deployed, reducing the risk of errors in production.
5. Focus on Analytics Engineering
DBT shifts the focus from traditional ETL to ELT (Extract, Load, Transform). With raw data already loaded into the warehouse, dbt allows teams to spend more time analyzing data rather than managing complex pipelines.
Real-World Use Cases
Data Cleaning and Enrichment: DBT is used to clean raw data, apply business logic, and create enriched datasets for analysis.
Building Data Models: Companies rely on dbt to create reusable, analytics-ready models that power dashboards and reports. DBT Online Training
Tracking Data Lineage: With its ability to visualize dependencies, dbt helps track the flow of data, ensuring transparency and accountability.
Conclusion
DBT has revolutionized the way data teams approach data transformations. By empowering analysts and engineers to use SQL for transformations, promoting collaboration, and leveraging the scalability of modern data warehouses, dbt has become a cornerstone of modern data engineering. Whether you are cleaning data, building data models, or ensuring data quality, dbt offers a robust and efficient solution that aligns with the needs of today’s data-driven organizations.
Visualpath is the Best Software Online Training Institute in Hyderabad. Avail complete Data Build Tool worldwide. You will get the best course at an affordable cost.
Attend Free Demo
Call on - +91-9989971070.
Visit: https://www.visualpath.in/online-data-build-tool-training.html
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://databuildtool1.blogspot.com/
#DBT Training#DBT Online Training#DBT Classes Online#DBT Training Courses#Best Online DBT Courses#DBT Certification Training Online#Data Build Tool Training in Hyderabad#Best DBT Course in Hyderabad#Data Build Tool Training in Ameerpet
0 notes
Text
Top Skills Every Data Science Student Should Master in 2024
If you're a student aspiring to build a thriving career in data science, you're not alone. With the demand for data scientists in India skyrocketing, learning the right data science skills is no longer a luxury—it’s a necessity. But where do you start, and which skills will truly set you apart in the competitive job market?
In this blog, we’ll break down the top data science skills for students and how mastering them can pave the way for exciting opportunities in analytics, AI, and beyond.
Why Learning Data Science Skills Matters in 2024
The future of data science is evolving fast. Companies are hunting for professionals who not only know how to build machine learning models but also understand business problems, data storytelling, and cloud technologies. As a student, developing these skills early on can give you a strong competitive edge.
But don’t worry—we’ve got you covered with this ultimate skills checklist to ace your data science career!
1. Python and R Programming: The Core of Data Science
Every data scientist’s journey begins here. Python and R are the most popular programming languages for data science in 2024. They’re versatile, easy to learn, and backed by huge communities.
Why Master It? Python offers powerful libraries like NumPy, pandas, and scikit-learn, while R excels in statistical analysis and data visualization.
Pro Tip: Start with Python—it’s beginner-friendly and widely used in the industry.
2. Data Wrangling and Preprocessing: Clean Data = Good Results
Real-world data is messy. As a data scientist, you need to know how to clean, transform, and prepare data for analysis.
Essential Tools: pandas, OpenRefine, and SQL.
Key Focus Areas: Handling missing data, scaling features, and eliminating outliers.
3. Machine Learning: The Heart of Data Science
Want to build predictive models that solve real-world problems? Then machine learning is a must-have skill.
What to Learn: Supervised and unsupervised learning algorithms like linear regression, decision trees, and clustering.
Bonus: Familiarize yourself with frameworks like TensorFlow and PyTorch for deep learning.
4. Data Visualization: Communicating Insights
Your ability to convey insights visually is just as important as building models. Learn tools like Tableau, Power BI, and Python libraries like Matplotlib and Seaborn to create compelling visualizations.
Why It Matters: Executives prefer dashboards and graphs over raw numbers.
5. SQL: The Backbone of Data Manipulation
Almost every data science job in 2024 requires SQL proficiency. It’s how you extract, query, and manipulate large datasets from relational databases.
What to Focus On: Writing efficient queries, using joins, and understanding database schema design.
6. Cloud Computing: The Future is in the Cloud
AWS, Azure, and Google Cloud are dominating the data science space. Knowing how to use these platforms for data storage, machine learning, and deployment is a game-changer.
Start With: AWS S3 and EC2 or Azure ML Studio.
7. Business Acumen: Turning Data into Decisions
Technical skills are great, but understanding business needs is what sets you apart. Learn how to frame data science problems in a business context and communicate your findings effectively to non-technical stakeholders.
Your Shortcut to Mastering Data Science Skills
Excited to start your journey? Learning these skills on your own can be overwhelming, but don’t worry—we’ve curated a list of the Top 10 Data Science Courses in Chennai that can help you master these in-demand skills faster. These courses are designed for students like you who want to learn data science the right way and land high-paying jobs.
Take the first step toward becoming a data scientist. Click the button below to explore our Top 10 Data Science Courses in Chennai and find the program that fits your learning style and career aspirations.
Explore Courses Now
Don’t wait—start building these skills today, and let your data science journey begin!
0 notes
Text
Google Looker Semantic Layer Facilitate Trustworthy AI In BI

Layer Looker semantics
AI enables intelligent applications and impacts corporate decisions, making accurate and trustworthy data insights more important than ever. Due to data complexity, volume, and variety of tools and teams, misinterpretations and mistakes may occur. Looker semantic layer-managed trustworthy definitions are needed. The semantic layer provides a consistent and business-friendly interpretation of your data using business knowledge and standardised references, ensuring that your analytical and Artificial Intelligence initiatives are based in reality and produce reliable results.
Looker semantic layer ensures clear, consistent language for your organisation and goods by providing as a single source of truth for business metrics and dimensions. The semantic layer eliminates ambiguity by translating vital signals to business language and user purpose, allowing generative AI technology to understand business logic rather than raw data and offer right responses. LookML (Looker Modelling Language) helps your firm create a semantic model that specifies data logic and structure, abstracts complexity, and makes it easier for users to find information.
Looker semantic layers are essential for gen AI. Gen AI used directly to ungoverned data can provide impressive but fundamentally incorrect and inconsistent results. It can miscalculate variables, arrange data, or misread definitions, especially when constructing complex SQL. Missed income and a bad strategy may result.
Every data-driven company needs accurate business data. Our internal testing shows that Looker semantic layer reduces data errors in gen AI natural language queries by two thirds. Enterprise Strategy Group determined that data consistency and quality were the main challenges for analytics and business intelligence solutions. Looker provides a single source of truth for the firm and all related apps, ensuring data accuracy and business logic.
The cornerstone of reliable Gen AI
For gen AI to be trusted, your company's data intelligence engine, the Looker semantic layer, must provide a centralised, regulated framework that describes your essential business concepts and maintains a single, consistent source of truth.
The Looker semantic layer is essential for trustworthy gen AI for BI, providing:
Trust: Ground AI responds in regulated, homogeneous data to reduce generative AI "hallucinations".
Deep business context: Data and AI bots should know your organisation like analysts. By teaching agents your KPIs, business language, and linkages, they may better understand client questions and respond appropriately.
Governance: Enforce your data security and compliance laws in gen AI to protect sensitive data and provide auditable access.
Organisational alignment: Implement data consistency throughout your company to ensure that users, reports, and AI-driven insights utilise the same ideas and vocabulary.
Gen AI semantic layer benefit
LookML, Looker's cloud-based semantic modelling language, has several crucial capabilities for integrating current AI with BI:
Experts may build metrics, dimensions, and join connections once and reuse them across Looker Agents, discussions, and users to ensure consistent replies and get everyone on the same page.
Deterministic advanced calculations: Looker eliminates chance and generates reproducible results, making it ideal for complex mathematical or logistical procedures. Dimensionalized measurements combine variables so you may operate on them together, making complicated jobs easier to execute.
Software engineering best practices: Looker uses version control and continuous integration to test and monitor code upgrades, keeping production apps running smoothly.
Built-in dimension groups enable time-based and duration-based calculations.
Deeper data drills: By evaluating one data point, drill fields allow users to go deeper. Data agents can utilise this to allow customers explore data slices.
With a Looker semantic layer, an LLM may focus on its strengths, such as searching through well-defined business objects in LookML (e.g., Orders > Total Revenue) instead of writing SQL code for raw tables with ambiguous field names. These elements can have human-friendly descriptions like “The sum of transaction amounts or total sales price”. This is vital when company clients say, “show me revenue,” rather than, “show me the sum of sales (price), not quantity.” LookML bridges the data source and decision-maker's priorities to enable LLMs find the correct fields, filters, and sorts data agents into sophisticated ad-hoc analysts.
LookML's well-organised library catalogue helps AI agents find relevant facts and summaries to answer your question. Looker must then obtain the data.
AI-BI promises intelligent, dependable, conversational insights. These changes may help their consumers across all Looker semantic layer data interaction surfaces. Google Cloud will add capabilities to conversational analytics, improve agent intelligence, and expand data source compatibility to make data interaction as easy and effective as talking to your favourite business advisor.
Conversational Analytics
Conversational Analytics uses Gemini for Google Cloud to speak with data. Conversational analytics lets non-business intelligence users ask data queries in natural language, pushing beyond static dashboards. Conversational analytics are available in Looker (Google Cloud core), Looker (original), and Looker Studio Pro.
Like the sample dialogue, Conversational Analytics allows natural, back-and-forth interaction. The user asks, “Can you plot monthly sales of hot drinks versus smoothies for 2023, and highlight the top selling month for each type of drink?” Conversational Analytics responds with a line graph showing 2023 smoothie and hot beverage sales, stressing July as the best month.
Conversational Analytics can interpret multi-part queries using common phrases like “sales” and “hot drinks,” as seen in this sample discussion. Users don't need to establish filter criteria or database column names like “Total monthly drink sales” or “type of beverage = hot.” Conversational Analytics responds with text, charts, and an explanation of its primary findings and rationale.
Main characteristics
Conversational analytics components include:
Looker (original) and Looker (Google Cloud core) users may utilise Conversational Analytics to ask natural language questions about Looker Explore data.
Conversational Analytics in Looker Studio lets you query supported data sources in natural language. needed Looker Studio Pro subscription.
Create and talk with data agents: Personalise the AI-powered data querying agent with context and instructions specific to your data to allow Conversational Analytics to offer more precise and contextually relevant responses.
Allow sophisticated analytics using Code Interpreter: The Conversational Analytics Code Interpreter converts your natural language queries into Python code and runs it. The Code Interpreter employs Python for more advanced analysis and visualisations than SQL-based searches.
Setting up and needs
Conversational Analytics in Looker Studio requires the following.
Membership in Looker Studio Pro is necessary. Looker users can get complimentary Looker Studio Pro licenses.
Administrators must activate Gemini in Looker Studio.
You and your Looker instance must meet these prerequisites to use Conversational Analytics:
Looker administrators must enable Gemini for the instance.
Your Looker admin must grant you the Gemini position. The querying model's access_data permission must also be in a role.
#Lookersemanticlayer#GoogleLooker#AIagents#ArtificialIntelligence#LLM#Gemini#GoogleCloud#ConversationalAnalytics#Python#LookerStudio#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
SQL Techniques for Handling Large-Scale ETL Workflows
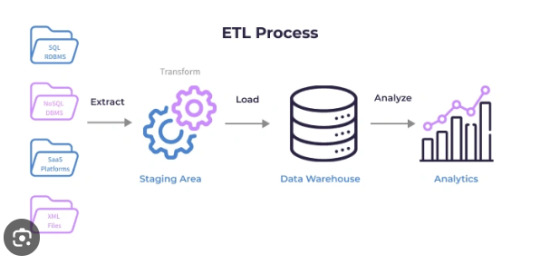
Managing and analyzing large datasets has become a critical task for modern organizations. Extract, Transform, Load (ETL) workflows are essential for moving and transforming data from multiple sources into a centralized repository, such as a data warehouse. When working with large-scale datasets, efficiency, scalability, and performance optimization are crucial. SQL, a powerful language for managing relational databases, is a core component of ETL workflows. This article explores SQL techniques for effectively handling large-scale Extract Transform Load SQL workflows.
Understanding the ETL Process
ETL workflows consist of three key stages:
Extract: Retrieving data from various sources, such as databases, APIs, or files.
Transform: Applying business logic to clean, validate, and format the data for analysis.
Load: Inserting or updating the processed data into a target database or data warehouse.
SQL is widely used in ETL processes for its ability to handle complex data transformations and interact with large datasets efficiently.
Challenges of Large-Scale ETL Workflows
Large-scale ETL workflows often deal with massive data volumes, multiple data sources, and intricate transformations. Key challenges include:
Performance Bottlenecks: Slow query execution due to large data volumes.
Data Quality Issues: Inconsistent or incomplete data requiring extensive cleaning.
Complex Transformations: Handling intricate logic across disparate datasets.
Scalability: Ensuring the workflow can handle increasing data volumes over time.
SQL Techniques for Large-Scale ETL Workflows
To address these challenges, the following SQL techniques can be employed:
1. Efficient Data Extraction
Partitioned Extraction: When extracting data from large tables, use SQL partitioning techniques to divide data into smaller chunks. For example, query data based on date ranges or specific IDs to minimize load on the source system.
Incremental Extraction: Retrieve only the newly added or updated records using timestamp columns or unique identifiers. This reduces the data volume and speeds up the process.
2. Optimized Data Transformation
Using Window Functions: SQL window functions like ROW_NUMBER, RANK, and SUM are efficient for complex aggregations and calculations. They eliminate the need for multiple joins and subqueries.
Temporary Tables and CTEs: Use Common Table Expressions (CTEs) and temporary tables to break down complex transformations into manageable steps. This improves readability and execution performance.
Avoiding Nested Queries: Replace deeply nested queries with joins or CTEs for better execution plans and faster processing.
3. Bulk Data Loading
Batch Inserts: Load data in batches instead of row-by-row to improve performance. SQL’s INSERT INTO or COPY commands can handle large data volumes efficiently.
Disable Indexes and Constraints Temporarily: When loading large datasets, temporarily disabling indexes and constraints can speed up the process. Re-enable them after the data is loaded.
4. Performance Optimization
Indexing: Create appropriate indexes on columns used in filtering and joining to speed up query execution.
Query Optimization: Use EXPLAIN or EXPLAIN PLAN statements to analyze and optimize SQL queries. This helps identify bottlenecks in query execution.
Partitioning: Partition large tables based on frequently queried columns, such as dates or categories. Partitioning allows SQL engines to process smaller data chunks efficiently.
5. Data Quality and Validation
Data Profiling: Use SQL queries to analyze data patterns, identify inconsistencies, and address quality issues before loading.
Validation Rules: Implement validation rules during the transformation stage to ensure data integrity. For example, use CASE statements or conditional logic to handle null values and invalid data.
6. Parallel Processing
Parallel Queries: Many modern SQL databases support parallel query execution, enabling faster data processing for large workloads.
Divide and Conquer: Divide large datasets into smaller subsets and process them in parallel using SQL scripts or database-specific tools.
Best Practices for Large-Scale ETL Workflows
Use Dedicated ETL Tools with SQL Integration: Tools like Apache Spark, Talend, and Informatica can handle complex ETL workflows while leveraging SQL for transformations.
Monitor and Optimize Performance: Regularly monitor query performance and optimize SQL scripts to handle growing data volumes.
Automate and Schedule ETL Processes: Use schedulers like cron jobs or workflow orchestration tools such as Apache Airflow to automate SQL-based ETL tasks.
Document and Version Control SQL Scripts: Maintain detailed documentation and version control for SQL scripts to ensure transparency and ease of debugging.
Advantages of SQL in Large-Scale ETL Workflows
Scalability: SQL is highly scalable, capable of handling petabytes of data in modern database systems.
Flexibility: Its ability to work with structured data and perform complex transformations makes it a preferred choice for ETL tasks.
Compatibility: SQL is compatible with most databases and data warehouses, ensuring seamless integration across platforms.
Conclusion
Handling large-scale Extract Transform Load SQL workflows requires a combination of efficient techniques, performance optimization, and adherence to best practices. By leveraging SQL’s powerful capabilities for data extraction, transformation, and loading, organizations can process massive datasets effectively while ensuring data quality and consistency.
As data volumes grow and workflows become more complex, adopting these SQL techniques will enable businesses to stay ahead, making informed decisions based on accurate and timely data. Whether you are managing enterprise-scale data or integrating multiple data sources, SQL remains an indispensable tool for building robust and scalable ETL pipelines.
0 notes
Text
Java Frameworks Decoded: Enrich Your Skills at Cyber Success Pune!

Java Programming:
In a fast-paced software world, becoming a full-service developer is a game changer. Cyber Success IT Training Institute, is pleased to announce our Java Course in Pune designed to provide you with the knowledge and skills you need to succeed in this dynamic field. Java is not only a programming language, it's simply a gateway to new things and there are unlimited possibilities in the software industry. At Cyber Success, we invite you not only to improve and sharpen your Java skills but also to pave the way for a successful career in software development. we explore the tips, techniques, and key features of Java programming that will not only enhance your coding skills but also pave the way for a successful career in software development.
Java programming is a versatile and powerful language, used in a wide range of applications, from web development to mobile application development. Completing our Certified Java course in Pune will open the door to even more opportunities in the tech world. Our accredited Java courses include all the necessary concepts and advanced aspects of Java programming, and ensure you have the skills and knowledge to excel in competitive tech in the field of employment. Whether you want to improve your coding skills or start your career in tech, our Java course in Pune is perfect for you. Join us at the Cyber Success Institute and embark on a journey of learning, development and endless possibilities in the world of Java programming.
Spring Program: Enabling Java Development
Java Programming is known for its versatility and ease of use, Spring is one of the most popular Java frameworks. It provides a comprehensive ecosystem of tools and features that facilitate the development of Java applications. Java frameworks like Spring and Hibernate have changed the vision of developers building applications, providing powerful tools and features that streamline the development process. At Cyber Success in Pune, we understand the importance of doing this program well to become a skilled Java developer. Join us as we explore the world of Java programming to learn how our Java Classes in Pune can help you master these powerful tools.
Key Features of Spring Framework:
Dependency Injection (DI): The Spring DI container controls dependencies of application components, making it easier to generate loosely coupled and testable code.
Aspect-Oriented Programming (AOP): The Spring AOP module allows developers to separate cross-cutting problems like logging and transaction management from the main application logic.
MVC Framework: Spring provides a robust MVC framework for developing web applications, making building RESTful services and web applications easy. Hibernate Framework: Simplifying Database Connectivity.
Hibernate is a powerful ORM (Object-Relational Mapping) framework that simplifies database connections in Java applications.
Key Features of Hibernate Framework:
Object-Relational Mapping: Hibernate maps Java objects to database tables, eliminating the need to write complex SQL queries.
Automatic table creation: Hibernate can create database tables based on Java classes automatically, reducing the need for manual database management.
Storage: Hibernate provides caching mechanisms to improve application performance by reducing the number of database requests.

Join Cyber Success in Pune: Your gateway to Java knowledge:
At Cyber Success, we offer advanced Java training Classes in Pune covering all aspects of Java programming, including popular programs such as Spring and Hibernate. Our course is designed to give you the skills and knowledge you need to succeed in the competitive world of software development. With experienced instructors, hands-on activities, and a supportive learning environment, Cyber Success is the perfect place to begin your journey to Java proficiency.
Key Features of Java Course in Pune at Cyber Success:
In-depth study of Java basics, advanced concepts, and popular frameworks like Spring and Hibernate.
Hands-on activities and exercises to reinforce learning and meaningful use.
Experienced teachers with industry experience and passion for teaching.
Supportive learning environment including access to resources and guidance.
Help with placement to help launch your career in software development.
Join us today!
If you are ready to take your Java knowledge to the next level, join us at Cyber Success in Pune. Together, we will explore the Java framework world and empower you to build powerful, efficient, scalable applications. Don’t just learn Java; Master it!
Enroll in our Java course in Pune and unlock your potential as a Java developer!
To know more in detail about the course syllabus visit,
https://www.cybersuccess.biz/all-courses/java-course-in-pune/
Register now to secure your future :
https: //www.cybersuccess.biz/contact-us/
📍*Our Visit: Cyber Success, Asmani Plaza, 1248 A, opp. Cafe Goodluck, Pulachi Wadi, Deccan Gymkhana, Pune, Maharashtra 411004
📞 *For more information, call: 9226913502, 9168665644.
“ YOUR WAY TO SUCCESS - CYBER SUCCESS 👍”
0 notes
Text
DBT AND SNOWFLAKE

Harnessing the Power of DBT and Snowflake: A Data Transformation Dream Team
Data (Data Build Tool) and Snowflake have emerged as indispensable players in the ever-evolving world of data analytics. When leveraged together, they form a dynamic duo that streamlines data transformation processes, driving efficiency and agility for organizations of all sizes.
What is debt?
dbt is a command-line tool that empowers data analysts and engineers to transform their data within their data warehouse. It employs SQL as its primary language, enabling users to focus on data modeling and building reliable pipelines while debt handles the intricate complexities. Critical features of DBT include:
Modularity: dbt promotes the creation of reusable data models, fostering code maintainability and scalability.
Version Control: Integration with Git allows you to track data transformation history, simplifying collaboration and rollbacks.
Testing: Built-in testing capabilities help guarantee the integrity and quality of your data.
Documentation: debt encourages code documentation, enhancing transparency and comprehension of your data pipelines.
What is Snowflake?
Snowflake is a cloud-based data warehouse built to meet the demands of modern analytics. Its unique architecture separates storage and compute resources, enabling cost-effective scaling. Salient features of Snowflake:
Performance: Snowflake delivers blazing-fast query performance, effortlessly handling large and complex data sets.
Scalability: Its elastic nature allows it to adapt to fluctuating workloads seamlessly.
Zero Administration: Snowflake’s fully managed cloud infrastructure eliminates the overhead of traditional data warehouse maintenance.
Accessibility: Snowflake’s SQL-based interface ensures familiarity for data professionals.
Why DBT and Snowflake Form a Winning Combo
The synergy between debt and Snowflake offers numerous advantages for data teams:
Streamlined Development: dbt’s SQL-centric approach aligns perfectly with Snowflake’s query engine, simplifying the Development and deployment of data pipelines.
Performance Optimization: Snowflake’s scalable computing resources provide ample power for data transformations orchestrated by debt.
Enhanced Agility: dbt’s modular structure and version control enable rapid prototyping, experimentation, and iterative Development directly within Snowflake.
Data Governance: DT’s testing and documentation capabilities and Snowflake’s security features support establishing robust data governance practices.
Putting It All Together: A Practical Example
Suppose you’re an analyst tasked with building a dashboard to track customer churn. Here’s how DBT and Snowflake can simplify this process:
Data Modeling: You’d define data models in SQL to clean, restructure, and join raw customer data from various sources in your Snowflake warehouse.
Testing: You’d incorporate debt tests to validate the accuracy and consistency of the transformed data.
Materialization: dbt would materialize the final transformation results as tables or views in Snowflake, optimized for dashboard visualization.
Deployment: DBT’s CI/CD integration capabilities help automate model deployment and updates to the Snowflake warehouse.
In Conclusion
Integrating data and Snowflake empowers teams to establish modern, scalable, and reliable data pipelines. By embracing this union, you’ll unlock new levels of efficiency, data quality, and timely insights, boosting your organization’s data-driven decision-making.
youtube
You can find more information about Snowflake in this Snowflake
Conclusion:
Unogeeks is the No.1 IT Training Institute for SAP Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Snowflake here – Snowflake Blogs
You can check out our Best In Class Snowflake Details here – Snowflake Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
0 notes
Text
Top Free AI GPT for PostgreSQL Database 2024

Are you looking for the best AI GPT tools to enhance your PostgreSQL database management? Look no further, as we have compiled a list of top free AI GPT tools specifically designed for PostgreSQL. These tools leverage the power of artificial intelligence to simplify query generation, optimize data analytics, and improve overall productivity. Let's explore the AI-driven solutions that can revolutionize your PostgreSQL experience. Key Takeaways: - Discover the best free AI GPT tools for PostgreSQL database management. - Leverage artificial intelligence to simplify query generation and optimize data analytics. - Improve productivity and efficiency with AI-driven solutions tailored for PostgreSQL. - Explore a range of tools, including AI2sql.io, AI Query, Outerbase, SQL Chat, and TEXT2SQL.AI. - Consider open-source SQL clients as alternative options for comprehensive database management. AI2sql.io AI2sql.io is an AI-driven SQL query generator that revolutionizes the way users interact with databases. By leveraging the power of natural language processing, AI2sql.io allows users to complete SQL queries using everyday language, eliminating the need for extensive coding knowledge. https://www.youtube.com/watch?v=QFvsaXO1LqI Whether you're a seasoned developer or a novice database user, AI2sql.io simplifies the query generation process by providing a user-friendly interface that understands and interprets your intent. With its seamless integration of OpenAI's GPT-3, AI2sql.io can intelligently analyze your queries and generate accurate SQL code. "AI2sql.io has truly transformed the way I work with databases. As someone who isn't well-versed in SQL, this AI-driven tool has made query generation a breeze. I can simply express my requirements in natural language, and AI2sql.io converts it into the appropriate SQL code. It's a game-changer!" - Jennifer Thompson, Data Analyst Designed to support popular databases like MySQL, PostgreSQL, and MongoDB, AI2sql.io offers a versatile solution for various database environments. Whether you're retrieving data, performing complex joins, or filtering results, this AI-driven SQL query generator enables you to express your requirements effortlessly. With its positive reception on Product Hunt and its ability to simplify the SQL query generation process, AI2sql.io has quickly gained popularity among data analysts, developers, and database administrators. By leveraging AI technology, this tool empowers users to focus on data analysis and decision-making rather than struggling with the intricacies of SQL coding. If you're looking for an efficient and user-friendly solution to boost your productivity and streamline your database workflows, AI2sql.io is the ideal tool for you. Experience the power of AI-driven SQL query generation and unlock the full potential of your PostgreSQL database. AI Query AI Query is an AI tool that harnesses the power of the GPT-3 model to generate SQL queries directly from natural language input. With its intelligent capabilities, AI Query offers a simplified approach to interact with databases and retrieve information effortlessly. This tool supports various databases, including PostgreSQL, MySQL, and SQL Server, providing flexibility for different database environments. One of the key features that sets AI Query apart is its intuitive visual interface. Users can define the structure of database tables and relationships using a visual representation, making it easier to understand and manipulate data. This visual approach eliminates the need for complex SQL syntax and empowers non-technical users to work effectively with databases. Whether you're a data analyst, developer, or database administrator, AI Query streamlines the process of generating SQL queries. By leveraging the GPT-3 model, it achieves better accuracy and efficiency in query generation compared to traditional methods. The AI's ability to understand natural language input allows users to express their queries in a more human-like manner, reducing the learning curve and increasing productivity. "AI Query has revolutionized the way we interact with our PostgreSQL database. Its visual interface is incredibly user-friendly, even for someone with little SQL knowledge. The ability to generate queries from simple natural language input has saved us a significant amount of time and effort." Example Use Case Let's say you have a PostgreSQL database containing customer information for an e-commerce platform, and you want to retrieve details for customers who have made a purchase in the past month. With AI Query, you can simply input a query like: Retrieve customers who made a purchase in the last month from the orders table. AI Query will analyze your query, understand your intention, and generate the corresponding SQL code: SELECT * FROM orders WHERE purchase_date >= current_date - INTERVAL '1 MONTH'; As illustrated in the table below, AI Query successfully translates your natural language query into a SQL query that retrieves the desired customer information: Customer ID Name Email 12345 John Doe [email protected] 56789 Jane Smith [email protected] AI Query simplifies the process of working with databases, allowing you to focus on insights and analysis rather than struggling with SQL syntax. The seamless integration of the GPT-3 model ensures accuracy and efficiency, enhancing your overall database experience. Outerbase When it comes to SQL clients, Outerbase stands out as a modern and intuitive tool designed to simplify database management. With its support for popular databases like Postgres, MySQL, and other relational databases, Outerbase offers a seamless experience for data analysts and business users alike. One of the key features that sets Outerbase apart is its minimal and user-friendly interface, resembling a spreadsheet. This familiar layout makes it easy for users to navigate and work with their data effectively. But what really makes Outerbase an exceptional SQL client is its AI-enhanced capabilities. Leveraging the power of AI, Outerbase helps users write SQL queries with efficiency and accuracy, reducing the time and effort required for complex database queries. The AI integration provides intelligent suggestions, auto-completion, and query optimization, allowing users to work smarter, not harder. In addition to query writing, Outerbase also offers AI-assisted insights. By analyzing database patterns and trends, Outerbase helps users uncover valuable insights and make data-driven decisions. This AI-driven approach brings a layer of intelligence to the SQL client, enabling users to extract maximum value from their databases. Outerbase empowers data analysts and business users to harness the full potential of their databases with its AI-enhanced capabilities. From simplifying query writing to uncovering valuable insights, Outerbase takes the complexity out of database management and puts data at your fingertips. Outerbase Key Features - Minimal and user-friendly interface - Supports popular databases like Postgres, MySQL, and other relational databases - AI-enhanced capabilities for efficient query writing - AI-assisted insights for data-driven decision-making Feature Description Minimal and user-friendly interface Resembles a spreadsheet, making it easy to navigate and work with data Supports popular databases Compatible with Postgres, MySQL, and other commonly used relational databases AI-enhanced capabilities Helps users write SQL queries efficiently with intelligent suggestions and auto-completion AI-assisted insights Analyzes database patterns and trends to uncover valuable insights for data-driven decision-making Outerbase is revolutionizing the way we interact with SQL clients, bringing AI-enhanced capabilities to streamline query writing and empower users with valuable insights from their databases. Whether you're a data analyst or a business user, Outerbase provides a powerful and intuitive platform for efficient database management and analysis. SQL Chat SQL Chat is a chat-based SQL client that leverages the power of natural language processing and AI to assist users in writing SQL queries. With its intuitive chat-based UI, users can interact with SQL Chat just like they would with a human chatbot, making query creation a breeze. SQL Chat supports a wide range of databases including MySQL, PostgreSQL, SQL Server, and TiDB Serverless. Whether you're a seasoned SQL expert or a beginner, SQL Chat's user-friendly interface simplifies the process of querying databases, making it accessible to all skill levels. But what sets SQL Chat apart is its integration with cutting-edge AI technology. It recently unveiled a new subscription model that allows users to choose between the advanced GPT-3.5 or the state-of-the-art GPT-4 models. These AI models have been trained on vast amounts of data and can understand and respond to complex SQL queries with remarkable accuracy. "SQL Chat has revolutionized the way I interact with databases. Its chat-based UI and powerful AI capabilities make SQL query writing a delightful experience!" Whether you're looking to retrieve data, join tables, or perform complex aggregations, SQL Chat has got you covered. By removing the need to memorize intricate SQL syntax, it saves users precious time and allows them to focus on the actual analysis. To give you a glimpse into the world of SQL Chat's AI capabilities, take a look at the following table highlighting some key features: Features Benefits Chat-based UI Easily construct SQL queries using natural language conversations. GPT-3.5 and GPT-4 Integration Leverage the power of advanced AI models to generate accurate SQL queries. Multi-database Support Query various databases such as MySQL, PostgreSQL, SQL Server, and more within a single interface. Query Suggestions Receive intelligent suggestions to enhance and refine your SQL queries. Data Visualization View query results in visually appealing charts and graphs for easier analysis. With SQL Chat's seamless integration of chat-based UI and AI capabilities, writing SQL queries has never been easier. Whether you're a developer, data analyst, or database administrator, SQL Chat empowers you to unlock the full potential of your databases. Discover a whole new way of interacting with your databases using SQL Chat and experience the future of SQL query generation. TEXT2SQL.AI TEXT2SQL.AI is an innovative and affordable AI tool designed to simplify SQL query generation for PostgreSQL databases. With its powerful capabilities and user-friendly interface, TEXT2SQL.AI streamlines the process of constructing SQL queries based on the database schema and user input. Supported by TEXT2SQL.AI, PostgreSQL database administrators and other users can effortlessly generate accurate and efficient SQL queries, saving valuable time and effort. Whether you are a data analyst, scientist, developer, or DBA, this AI tool can significantly enhance your productivity and overall data management experience. One of the standout features of TEXT2SQL.AI is its versatility. Not only does it support PostgreSQL, but it also caters to a wide range of other popular databases, including MySQL, Snowflake, BigQuery, and MS SQL Server. This compatibility ensures flexibility and convenience for users working with various database systems. Additionally, TEXT2SQL.AI offers more than just SQL query generation. This comprehensive tool also has the capability to generate regular expressions, Excel formulas, and Google Sheets formulas, making it a valuable asset for data manipulation and analysis beyond SQL queries. TEXT2SQL.AI sets itself apart from other SQL AI tools by providing an affordable solution without compromising on functionality or performance. By offering an accessible and cost-effective option, TEXT2SQL.AI aims to empower individuals and organizations of all sizes to leverage the power of AI for their PostgreSQL databases. In summary, TEXT2SQL.AI is a powerful and affordable SQL AI tool that caters to PostgreSQL databases and various other popular database systems. By simplifying SQL query generation and offering additional features like regular expressions and formula generation, TEXT2SQL.AI enhances productivity and efficiency for data professionals across different industries. Open Source SQL Clients This section explores some of the top open source SQL clients available that offer a range of features and support for various databases, including PostgreSQL and MySQL. These clients provide users with powerful tools to efficiently manage and interact with their databases. DBeaver DBeaver is a widely used open source SQL client that supports multiple databases, including PostgreSQL and MySQL. It offers a user-friendly interface and a rich set of features, such as syntax highlighting, code completion, and data visualization. DBeaver also allows users to securely connect to databases and manage database objects and queries effectively. Beekeeper Studio Beekeeper Studio is another popular open source SQL client that offers a streamlined and intuitive interface. It supports various databases, including PostgreSQL and MySQL, and provides essential features like code editors, table and schema navigation, and query history. Beekeeper Studio also offers a plugin system that allows users to extend its functionality based on their specific requirements. DbGate DbGate is an open source SQL client that offers a simple and efficient user interface, making it easy for users to manage PostgreSQL and MySQL databases. It provides features like query execution, table management, and data import/export capabilities. DbGate also offers a data browser that allows users to explore database tables and execute queries in a user-friendly environment. Sqlectron Sqlectron is an open source SQL client that supports various databases, including PostgreSQL and MySQL. It offers a lightweight and easy-to-use interface, allowing users to connect to multiple databases and execute queries efficiently. Sqlectron also provides features like syntax highlighting, query history, and result exporting to enable seamless database management. HeidiSQL HeidiSQL is a powerful open source SQL client that supports databases like PostgreSQL and MySQL. It offers a comprehensive set of features, including query editing, database administration, and data manipulation. HeidiSQL also provides advanced functionalities like session management, server monitoring, and SSH tunneling for secure database access. phpMyAdmin phpMyAdmin is a popular open source SQL client specifically designed for managing MySQL databases. It offers a web-based interface that allows users to perform essential database tasks like creating tables, executing queries, and managing user permissions. phpMyAdmin also provides functionalities like visual query builder, data import/export, and database operations logging. pgAdmin pgAdmin is a comprehensive open source SQL client designed specifically for managing PostgreSQL databases. It provides a feature-rich interface that allows users to perform tasks like query execution, schema management, and table editing. pgAdmin also offers advanced functionalities like server administration, data backup and restore, and a visual query builder to enhance database management capabilities. These open source SQL clients empower users to efficiently interact with their databases, execute queries, and perform various database management tasks. Their broad range of features and support for diverse databases, including PostgreSQL and MySQL, make them valuable tools for developers, data analysts, and database administrators. SQL Client Supported Databases Features DBeaver PostgreSQL, MySQL, and more Syntax highlighting, code completion, data visualization Beekeeper Studio PostgreSQL, MySQL, and more Code editors, table navigation, query history DbGate PostgreSQL, MySQL, and more Query execution, table management, data import/export Sqlectron PostgreSQL, MySQL, and more Syntax highlighting, query history, result exporting HeidiSQL PostgreSQL, MySQL, and more Query editing, database administration, data manipulation phpMyAdmin MySQL Web-based interface, visual query builder, import/export pgAdmin PostgreSQL Query execution, schema management, server administration Conclusion When it comes to enhancing data management and analytics in PostgreSQL databases, SQL AI tools are invaluable. AI2sql.io, AI Query, Outerbase, SQL Chat, and TEXT2SQL.AI offer AI-driven capabilities that provide automation, natural language query generation, and AI-assisted SQL writing. These tools have the potential to significantly improve productivity and efficiency for data analysts, data scientists, developers, and DBAs. By leveraging AI technology, they streamline the process of working with PostgreSQL databases, allowing users to interact with the data in a more intuitive and efficient manner. However, while these tools have their strengths, it's important to double-check the results for accuracy. As with any AI-generated output, there may be instances where human review and intervention are necessary to ensure the accuracy and integrity of the queries generated. Additionally, it is crucial to not overlook traditional options for database management. Open source SQL clients like DBeaver, Beekeeper Studio, and pgAdmin also offer comprehensive features for database management and can be powerful tools for working with PostgreSQL databases. Overall, the best AI GPT for PostgreSQL and PostgreSQL AI integration depends on individual needs and preferences. It is advisable to explore and experiment with different tools to find the optimal solution that aligns with your specific requirements and enhances your PostgreSQL database management experience. FAQ What is AI2sql.io? AI2sql.io is an AI-driven SQL query generator that supports popular databases like MySQL, PostgreSQL, and MongoDB. How does AI2sql.io work? AI2sql.io integrates with OpenAI's GPT-3 to allow users to use natural language to complete SQL queries. What is AI Query? AI Query is an AI tool that uses the GPT-3 model to generate SQL queries from natural language input. It supports databases like Postgres, MySQL, and SQL Server. What are the standout features of AI Query? AI Query has a visual interface that allows users to define the structure of database tables directly. What is Outerbase? Outerbase is a modern SQL client designed for data analysts and business users. It supports databases like Postgres, MySQL, and other relational databases. What are the AI-enhanced capabilities of Outerbase? Outerbase offers AI-enhanced capabilities to assist with writing SQL queries and gaining insights from the database. What is SQL Chat? SQL Chat is a SQL client that integrates with ChatGPT to help users write SQL queries. It supports databases like MySQL, PostgreSQL, SQL Server, and TiDB Serverless. What are the recent updates to SQL Chat? SQL Chat recently introduced a subscription model and the option to choose between the GPT-3.5 or GPT-4 models. What is TEXT2SQL.AI? TEXT2SQL.AI is an AI tool that generates SQL queries based on database schema and user input. It supports databases like MySQL, PostgreSQL, Snowflake, BigQuery, and MS SQL Server. What are the notable features of TEXT2SQL.AI? TEXT2SQL.AI is known for its affordability and the ability to generate SQL as well as regular expressions, Excel, and Google Sheets formulas. What are some popular open-source SQL clients for PostgreSQL and MySQL? Some popular open-source SQL clients include DBeaver, Beekeeper Studio, DbGate, Sqlectron, HeidiSQL, phpMyAdmin, and pgAdmin. How can AI GPT tools benefit PostgreSQL database users? AI GPT tools like AI2sql.io, AI Query, Outerbase, SQL Chat, and TEXT2SQL.AI Read the full article
0 notes